
Machine Learning

The rapid improvements in the Large Language Models (LLMs) have successfully transformed the artificial intelligence domain. GPT models of the OpenAI honed on the maximum online data and enabled users to interact with all artificial intelligence-powered systems. However, they may provide outdated or inaccurate information.
The Retrieval Augmented Generation (RAG) is an advanced approach to natural language processing and artificial intelligence. This innovative framework combines all the positive aspects of the retrieval-based and generative models. It also modernises how artificial intelligence systems understand and makes human-like text.
The RAG is an artificial intelligence framework designed to retrieve facts from an external knowledge base to the complete ground LLMs on up-to-date and accurate information. It enhances the quality of RAG LLM-generated responses as it grinds the model on the overall external knowledge sources and supplements the internal representation of information of LLMs. It ensures that the complete model has access to the reliable and current facts that users expect to access to the sources of the model. It ensures that its claims can be verified for accuracy.
Users of the RAG do not have to regularly train the model on new data and update its parameters. They can save the computational and financial costs of running their large language model-powered chatbots in their enterprise setting.
Retrieval-augmented generation (RAG) is an advanced architecture designed for combining the capabilities of a large language model, especially ChatGPT. It adds an information retrieval system that provides the most up-to-date and accurate data to users. It is a modern AI technique for enhancing the quality of generative AI by allowing the LLMs to tap extra data sources devoid of retraining.
RAG models successfully build knowledge repositories as per the data of the organization and the repositories can be regularly updated to assist the generative AI to provide contextual and timely answers. Almost every conversational system and chatbot using natural language processing nowadays gets remarkable benefits from RAG and generative AI.
The world-class technologies such as vector databases are associated with the RAG implementation. This method lets rapid coding of new data and the overall searches against the data feed into the large language models.
Principal of RAG
The RAG model works on the principle of leveraging external knowledge sources in the form of text and augmenting the neural model's capabilities. Unlike other models, RAG has the capability of pulling the information dynamically from external sources instead of relying on the information stored in external sources during the training phases.
Core Mechanisms of RAG
RAG (Retrieval-augmented generation) works by combining the pre-trained language models and retrieval mechanism. The retrieval mechanism acts as a connecting bridge for language models and external sources where information is stored. It helps RAG models to generate accurate, relevant, and up-to-date content.
The key components of the retrieval augmented language model are the generator model and the retrieval model. They are configured and fine-tuned based on the application. They make the RAG model a very powerful and incredibly flexible tool. They provide the RAG with enough capabilities to source, synthesise, and make information-rich content.
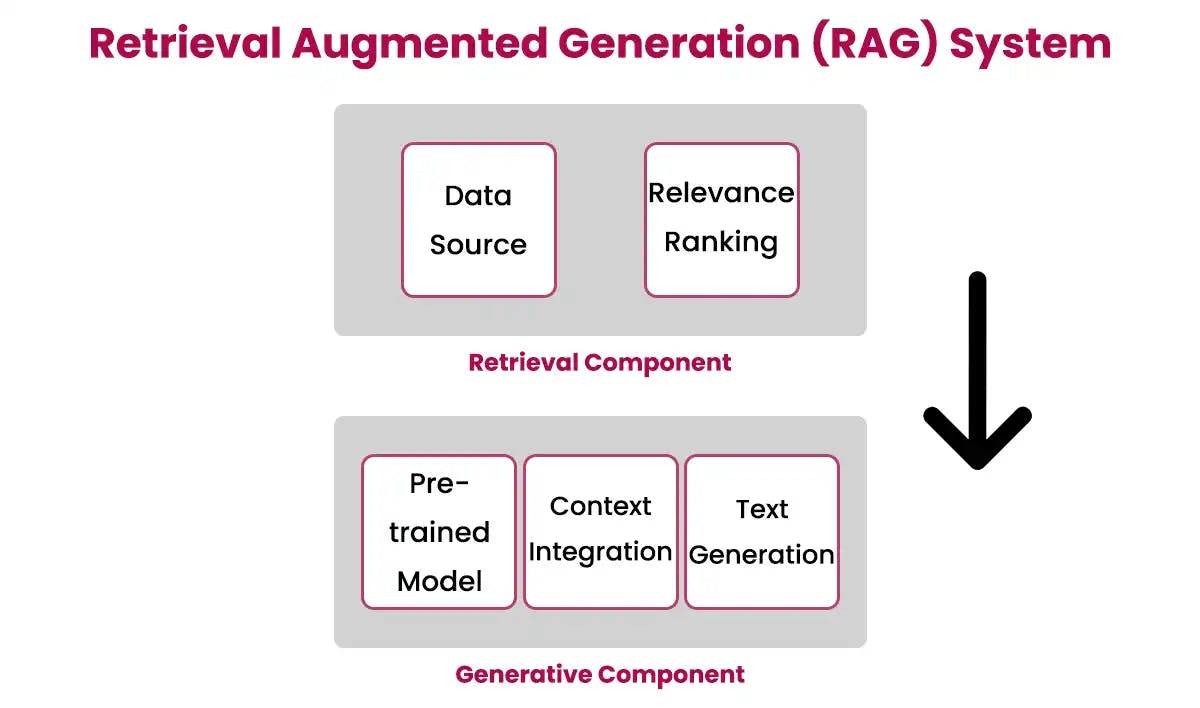
The generative model of the rag ai comes into play when the retrieval model has successfully sourced the relevant information. It acts as a creative writer and synthesises the retrieved information into coherent and contextually relevant text. It is built upon the LLMs and is known for its capability to make text that is semantically meaningful, grammatically correct, and aligned with the initial prompt or query. It takes the raw data chosen by the retrieval model and gives it a good narrative structure to make the information actionable. It serves as the last piece of the puzzle and gives the textual output we deal with.
The retrieval model acts as the information gatekeeper in the retrieval-augmented generation architecture. The main purpose of this model is to search through a large collection of data to find associated information that can be used for successful text generation. It uses the best algorithms to rank and choose the most relevant data.
The model offers a method to introduce external knowledge into the text generation process. It sets the stage for informed and context-rich language generation. It elevates the traditional language models’ capabilities. It can be implemented using several mechanisms like vector search and vector embedding.
A retrieval-augmented generation implementation includes three components namely input encoder, neural retriever, and output generator. An input encoder encodes the input prompt into a collection of vector embedding for the complete operations downstream. A neural retriever retrieves the most related documents from the external knowledge base as per the encoded input prompt.
Once the documents are indexed, they are chunked. This is the main reason why only the most relevant documents are appended to the prompt. The output generator component makes the final output text. It takes into account the encoded input prompt and the retrieved documents. It is usually a foundational LLM similar to Claude and ChatGPT. These three components are implemented using the pre-trained transformers. These transformers are a type of neural network and are known for their effective nature for natural language processing tasks.
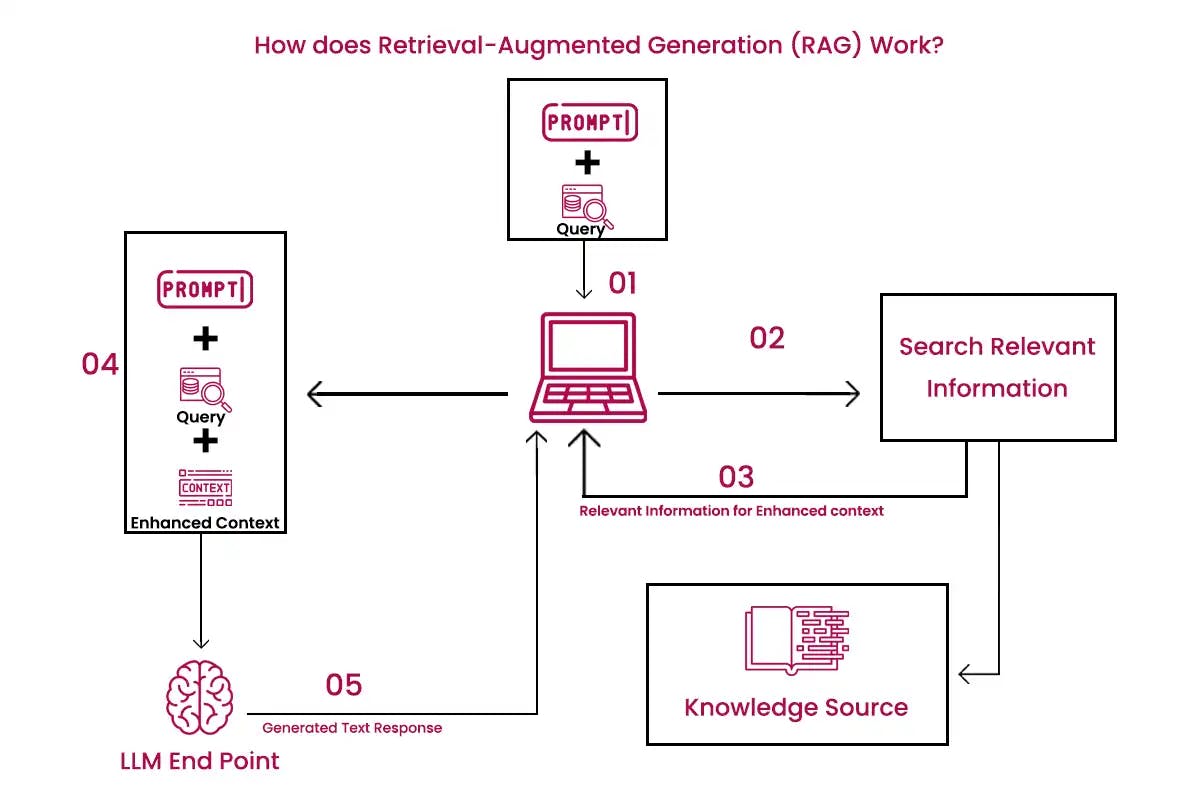
The input generator and output generator in the RAG are fine-tuned for particular tasks. However, the neural retriever is pre-trained on a large amount of data and code to enhance its ability to retrieve relevant documents.
In retrieval augmented generation rag, the dynamic data like the news feeds, blogs, and chat transcripts from past customer service sessions, unstructured PDFs, and structured databases of the organisation are translated into the common format. These data are stored in the knowledge library accessible to the generative artificial intelligence system. They are processed into numerical representation by using an algorithm known as an embedded language model and stored in the vector database. The data in the vector database can be immediately searched and used to retrieve the correct information.
The RAG delivers original, accurate, and relevant responses by integrating retrieval and generative AI models. Everyone in the artificial intelligence development company uses the RAG as efficiently as possible. The RAG models properly understand the context of queries and make unique and fresh replies by mixing both models. They are more accurate than previous models, better at synthesising information, adept at putting information into context, easy to train, and most efficient.
All new and regular users of the retrieval augmented generation in the artificial intelligence development company nowadays get more than expected benefits. They are happy to use and suggest the RAG to others. If you like to get enhanced text quality and coherence for your search results, then you can prefer and use the RAG hereafter. The RAG models scale by updating the external database and providing accurate information as expected by users.
The RAG has absolute access to fresh information. The data present in the knowledge repository of the RAG are regularly updated. This process does not incur any cost. It includes more contextual data than the information in the usual LLMs.
There are so many applications of the RAG today. If you explore various aspects of these applications, then you can decide to use the RAG hereafter. You will become a happy user of the RAG.
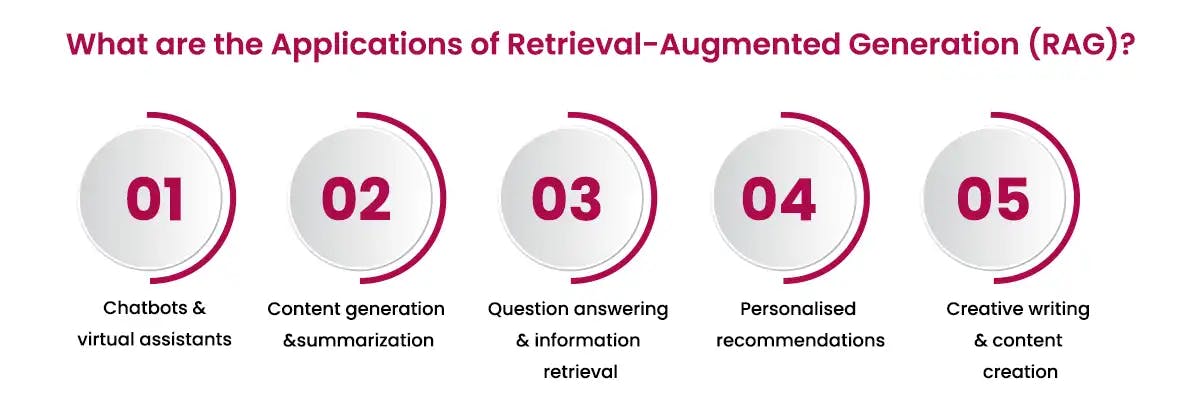
Beginners and regular users of the language learning model have to concentrate on and keep up-to-date with the top retrieval-augmented models. The following details explain these models.
The latest updates of ChatGPT and ChatGPT-IR help every user to retrieve important and relevant information. If you decide to immediately get the information in any category, then you can use the ChatGPT with ChatGPT-IR.
RAG is a very good strategy designed to help address both hallucinations of LLM and out-of-date training data. You can research the fundamentals of the RAG and focus on the main benefits of the RAG in detail now. You will make a good decision to use it.
There are so many case studies revealing the practical applications of the RAG. Here are some attractive examples, take a look.
Cohere
The Canadian-based multinational technology company well known as the leading company in the field of generative AI and RAG has provided a chatbot that offers contextual details and fact-based information to customers about a vacation trip to the Canary Islands. The chatbot was developed to deliver in-depth answers about beach accessibility, beach lifeguards, and the availability of nearby gaming courts.
Similarly, one of the leading tech giants Oracle uses RAG for analysing financial reports, finding natural gas and oils, cross-checking customer exchange transcripts from the call center, and analysing medical databases to find relevant research papers.
The RAG training and data-related activities have to be enhanced further to give outstanding benefits to all users. It synthesises data by mixing relevant information from the generative and retrieval models to produce a response.
As a beginner to the RAG challenging things, you have to focus on the redundancy at first. RAG users are unable to avoid redundant information retrieval and superfluous repetition in the generated content. The two-step process of information retrieval and generation leads to a computationally intensive nature. It poses challenges for all real-time applications. If the retrieval model in the RAG fails to choose the most relevant documents, then it negatively impacts the final output.
Take a look at some common challenges associated with the RAG approach.
RAG comes to the rescue by properly melding the LLMs’ generative capabilities with real-time, targeted data retrieval devoid of altering the underlying model. Here are the lists of some promising future trends of RAG technology in retrieval augmented generation.
RAG raises ethical concerns especially privacy issues and misinformation propagation. As a user of the RAG, you have to ensure the below-mentioned ethical and responsible usage.
RAG represents a paradigm shift in machine learning and brings a distinctive blend of retrieval and generation methods. Every user of this RAG is happy about its impressive scalability, accuracy, and versatility. It shapes the future of artificial intelligence-powered language understanding and generation by bolstering transparency without any data leakage.
The RAG model can access real-time data along with the contextualization and enhancement of AI-generated responses. This empowers AI to deliver more accurate and context-aware content.
Codiste is an expert in AI development-based software either LLM or RAG. It is dedicated to providing the best-in-class RAG applications as per the expectations of every client. You can contact and consult with an experienced team in this company to get customized services at reasonable prices.




Share your project details with us, including its scope, deadlines, and any business hurdles you need help with.
Countries Served Globally
Technocrat Clients
Repeat Client Rate